
Oracle Analytics Cloud falls in the category of augmented analytics, which automates insights using Machine Learning, a platform to quickly leverage Machine Learning algorithms and powerful visualizations.
When things are growing at an unprecedented pace, How can one bring Machine Learning to a business user or an ML enthusiast or someone who wants quick results?
- By keep on adding Smart features —Wherever AI/ML algorithms can be embedded in the app. which helps users leverage automated ML features just by a click.
- By providing a GUI based platform with all the ML algorithms available at this point in time— so that user can drag and drop the existing algorithms and execute them without the need of writing code.
Before we look at these features further, Lets look at a business problem and try solving it using these features.
Problem statement:
The data is related to direct marketing campaigns of a Portuguese banking institution.The marketing campaigns were based on phone calls. Objective is to predict customers, who would accept the bank term deposit or not. Which helps the campaign team in contacting customers who are likely to accept the offer than everyone.
OAC project file .dva along with the data is available here, you can export it in either oracle data visualization desktop (DVD) or oracle analytics cloud (OAC).You can create an oracle account and download DVD from here for free.
- Smart features: Explain, Recommendations, Outliers and Clusters..etc
Explain — Explains you a column’s basic facts, drivers, anomalies ..etc
Recommendations — gives you recommendations in data preparation stage.
Outliers — shows the outliers in the data that’s selected
Clusters — Identifies the clusters in the data.
Lets look at the ‘Explain’ feature
It does analysis for us and tries to explain us both visually and via text. Explanation starts with basic facts of the column ‘y’ and its drivers, segments and even anomalies.
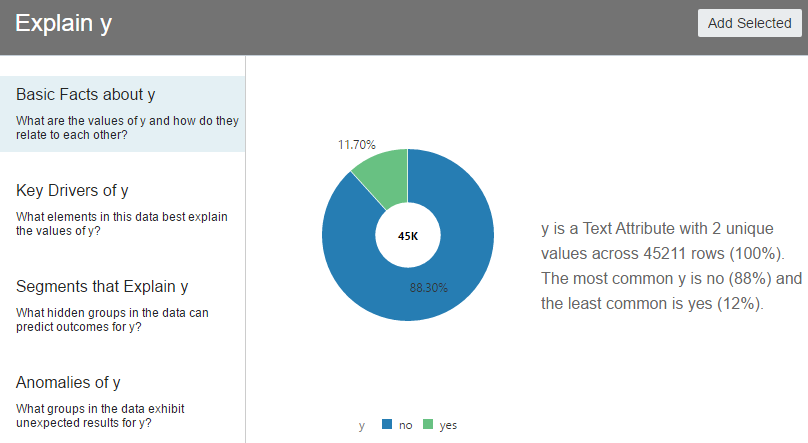
It also explains the anomalies, drivers and if there are any segments that could explain the column ‘y’.
2. GUI based platform with all the ML algorithms:
Oracle Analytics provides algorithms in all four major Machine Learning categories from Regression, Classification, Clustering and Association Rule Mining. In order to solve our business problem of ‘predicting customers bank term deposit acceptance’, let us go with the traditional data science pipeline approach.
Data science pipeline:
Let me show, how you can leverage the full data science pipeline,

- Data Loading
Burger Menu->Data->Data flow -> Create Data flow ->Data flow-> Add data
You can find the data if you have added already before here, else you can either upload from the local machine or connect to other sources from 50 built-in connectors.

As my data is on my local machine I can just drag and drop the csv file,

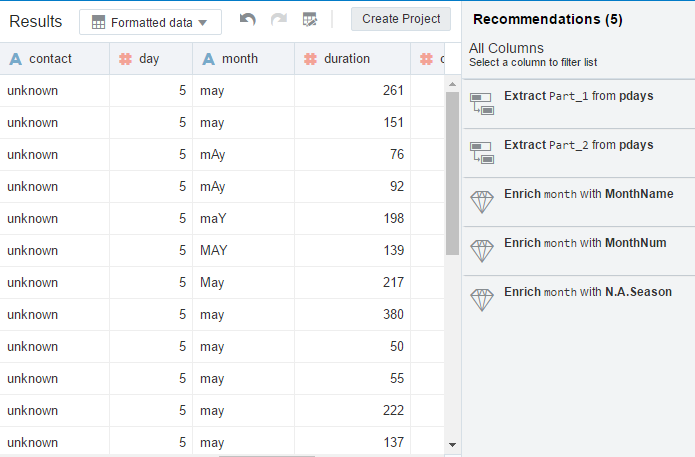
As soon as you add the data, we could see the built-in recommendations feature on the right. It says, would you like to extract a part from the column? or would you want me to enrich the month column as it is inconsistent. Just click on it will convert it for you, which saves a lot of time and effort.
let’s see how that looks like, just click on enrich month it creates a new column with a consistent month format. As you can say the month column has ‘mAy,MAY,may,..etc’ all are converted to unified format ‘May’ in a new column next to it ‘month_MonthName’.
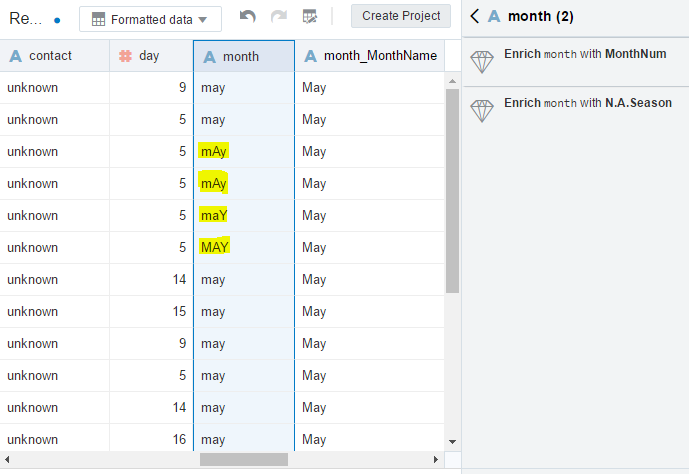
If the results are as you expected, click on apply script and proceed. This saves us a lot of time and effort in data cleaning. In fact, Data preparation accounts for about 80% of the work of data scientists. However, you can further prepare by right clicking on each column.

2. Exploratory Data Analysis
To explore visually and understand the data, we can start off by quickly leveraging the built-in features, Lets use Explain feature on ‘Y’ (Outcome of the marketing event)

When you click on key drivers and It says that there are three columns which are strongly correlated with Y. Like poutcome(previous event’s outcome), month (last contacted month) and loan (whether the client has a personal loan or not). In other words it says, “Whether a client subscribes the term deposit also depends on his choice in the previous campaign and whether he has a loan or not.” which is very valuable analysis in short time. This analysis can be used as a starting point or do your own analysis by various visualizations.

Let’s look at one visualization,

3. Data preparation
You can create a data flow and select the columns that you would want to feed for your algorithm.

4. Modeling
Since our target is the column ‘y’, that says yes or no (whether the customer to subscribed a term deposit or not). Because our target is binary variable,Its a binary classification problem. let’s click on the ‘Train Binary classifier’ and proceed.
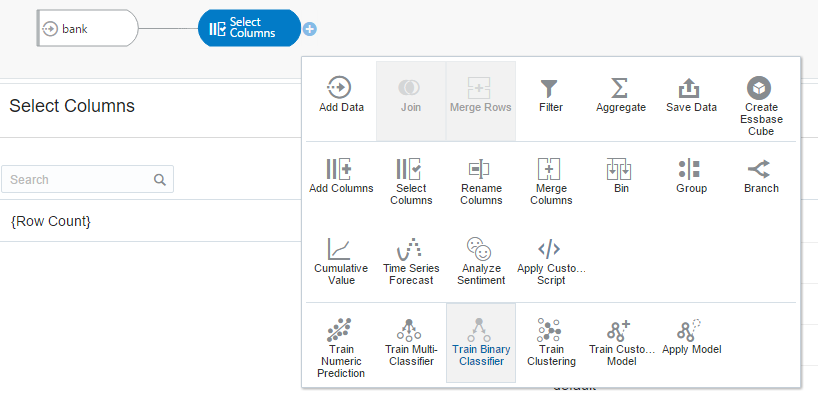
Pick one among the classification algorithms.
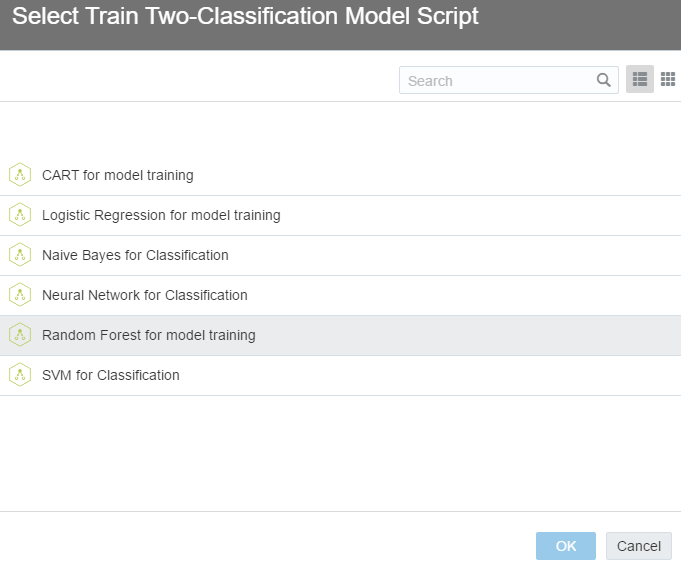
You can play with algorithm parameters, if you would like to.


I saved the model as BM_Classifier.
5. Model Evaluation
You can click on Machine Learning and find the binary classification model that we created.
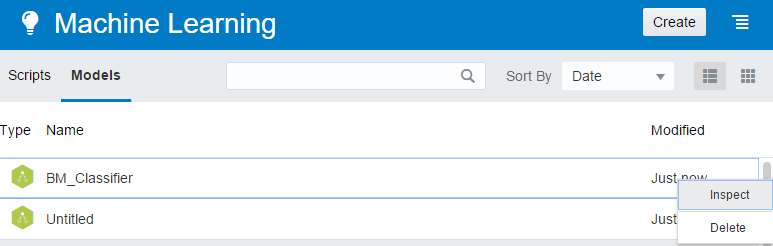
Inspect on the model to see the quality of model, since it is a classification model we can see the confusion matrix.
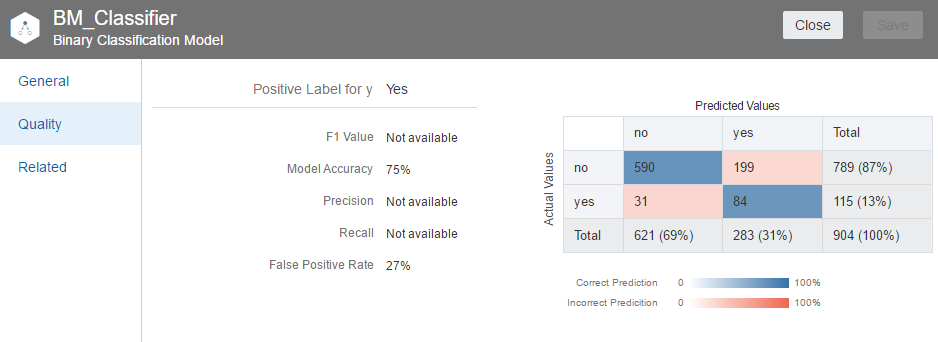
Here the accuracy of the model is 75%, you can fine tune model parameters further and achieve better results.
6. Model Prediction
To test the model for new costumers, you can upload the data set of new customers and create a new data flow and instead of selecting a model, you would say apply and select BM_Classifier model.

And the results can be added to our canvas.

Based on the trained model. Among the four customers, I can go ahead and contact this one customer who is very likely to subscribe.
The dataset used is available for research. [Moro et al., 2011] S. Moro, R. Laureano and P. Cortez. Using Data Mining for Bank Direct Marketing: An Application of the CRISP-DM Methodology.
